The Causal Roadmap
Causal inference series
We do a bad job teaching statistics

DAGs and observations
A directed acyclic graph (or DAG or just graph) conveys our assumptions about the mechanisms that gave rise to the observations, e.g.,
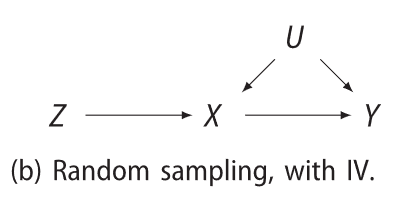
This is a functional causal model \(\{F_V:pa(V)\times U_V\to V\mid V\in\mathcal{V}\}\), e.g., \(y = F_Y(x, u, \varepsilon_Y)\).
Note
There are other frameworks for specifying a causal model, this is just one of them (the “Pearl model”, aka, NPSEM-IE).
The main other one that has led to many results in the causal literature is the Neyman/Rubin potential outcomes framework.
What makes a good causal parameter?
The answer is complicated, see Colnet et al. (2023) Risk ratio, odds ratio, risk difference… Which causal measure is easier to generalize?

Some key tips:
- Choose something meaningful/interpretable to you, consider the statistical distribution of the outcome and what would be useful summary statistics (e.g., mean, median, probability of exceeding a threshold)
- Do not use the odds nor hazard ratio because it they are not logic respecting, i.e., the measure in the full population can be outside the range of measures defined in subpopulations (generally considered to be a paradox)