Introduction to knitr
Michael Sachs
Programs are meant to be read by humans and only incidentally for computers to execute.
- Donald Knuth
Motivation
The cut-and-paste approach to report production is tedious, slow, and error-prone. It can be very harmful to reproducible research and it is inconvenient to reproduce results.
knitr is an R package that integrates computing and reporting. By incorporating code into text documents, the analysis, results and discussion are all in one place. Files can then be processed into a diverse array of document formats, including the important ones for collaborative science: pdfs, Word documents, slide presentations, and web pages.
This is important for reproducible research because you can create reports, papers, presentations in which every table, figure, and inline result is generated by code that is tied to the document itself. It makes life easier when it comes time to make small updates to an analysis, and more importantly, the code becomes more understandable by virtue of being directly related to the text description.
The importance of text
There are many advantages to creating scientific content using simple text documents. For one, they are future-proof. Microsoft and Apple are continually updating their software and document formats. In 5 years I probably won’t be able to easily open a Word document that I created today, and likewise, when a new document format comes out (remember when .docx was new?) it takes a while for it to be widely adopted. It is highly unlikely that text documents will become obsolete. I can still open a text file that I created on my old Apple IIe. Secondly, content tracking tools like git and github work wonderfully with text files. It is dead-easy to view line-by-line changes in a text file.
Tools like knitr, rmarkdown, and pandoc do the hard work of translating your text files into “production” documents, like beautifully typeset pdfs, smooth presentations, and Word documents that your collaborators can’t live without. Creating the base in a text file allows you to focus on the content and not obsess over the details like formatting and figure placement. This document was created with knitr in markdown. Check out the source code here.
How to use knitr
The basic idea is that your text documents are interrupted by chunks of code that are identified in a special way. These chunks are evaluated by an R process in the order that they appear. R objects that are created by chunks remain in the enviroment for subsequent chunks. The code in the chunks is displayed and formatted in the document. The results printed by the code are also incorporated into the document as figures, tables, or other objects. Chunks can stand alone, or be included inline with text. Many options exist to format the code and the results, and the options can be extended in countless ways.
How exactly to use knitr depends on the input document format. First I will desribe how to use it with markdown.
knitr with markdown
When I say markdown I am referring to the plain text formatting syntax, as opposed to the software. Markdown is a syntax closely related to html. It is semanic, like html, but it is much less verbose. Markdown documents can in fact stand on their own as readable text documents without being rendered. Semantic means that elements of the document are described by what they represent, as opposed to how they should look. Thus, for a title, you indicate that this text is the title, as opposed to this text should be large font and in bold. Here is an example with the result:
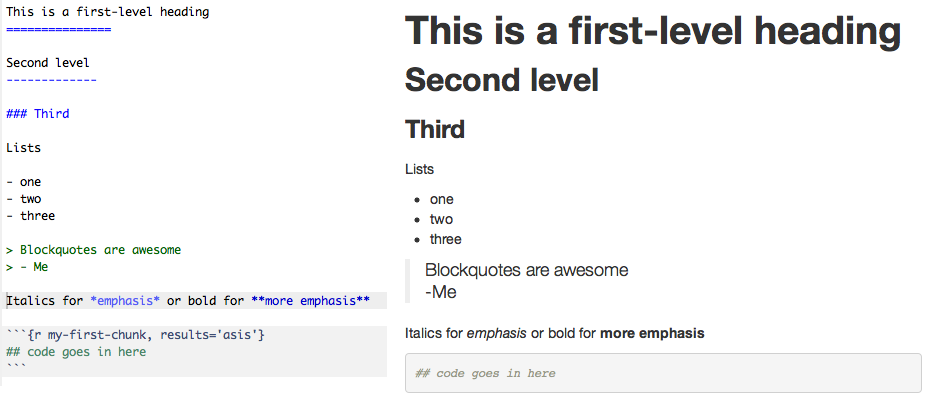
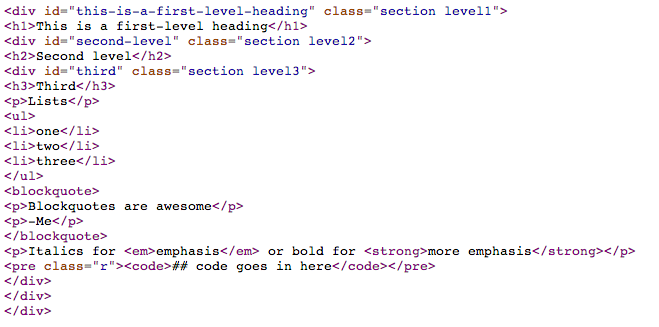
Importantly, the markdown can stand on its own and continue to be readable even though it’s a simple text file. Contrast that with the generated html:
Or the equivalent Latex:
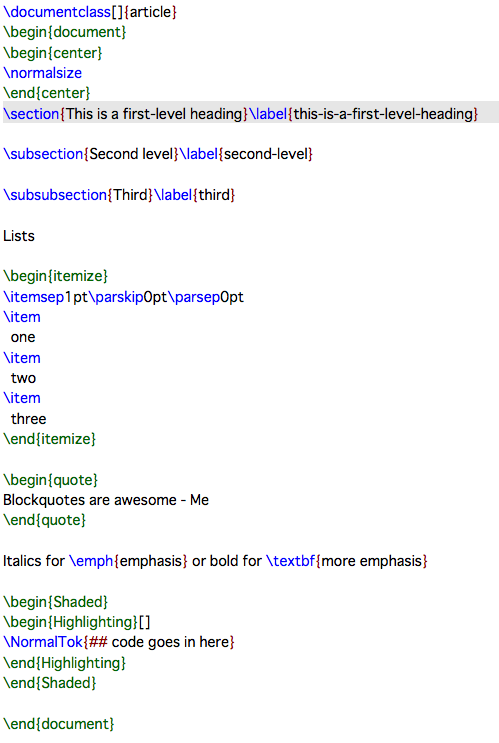
Thus markdown has the dual advantages of being readble on it’s own, and having associated tools to create other document formats from it. Math in markdown is just like math in Latex.
Incorporating code chunks
In markdown, the start of a code chunk is indicated by three backticks and the end of a code chunk is indicated by three backticks. At the start of the chunk, you tell knitr what type of code it is, give the chunk a name, and other options:
```{r my-first-chunk, results='asis'}
## code goes in here
```Inline code is similar, using single backticks instead. Inline code does not have names or options. For example, r rnorm(10).
Here’s an example of raw output using the mtcars dataset:
```{r mtcars-example}
lm(mpg ~ hp + wt, data = mtcars)
```##
## Call:
## lm(formula = mpg ~ hp + wt, data = mtcars)
##
## Coefficients:
## (Intercept) hp wt
## 37.2273 -0.0318 -3.8778And here’s a plot
```{r mt-plot}
library(ggplot2)
ggplot(mtcars, aes(y = mpg, x = wt, size = hp)) + geom_point() + stat_smooth(method = "lm", se = FALSE)
```
The concept is very simple. Anything you want to do in R is incorporated into your document, the results alongside the code. The important details to learn are methods of controlling the output. This means making nice looking tables, decent figures, and formatting inline results. We will cover these topics next.
Controlling R output
Tables
When outputting tables in knitr, it is important to use the option results = 'asis'. There are several options for formatting tables in R. The knitr package includes a function called kable that makes basic knitr tables. There are options to control the number of digits, whether row names are included or not, column alignment, and other options that depend on the output type.
```{r kable, results = 'asis'}
kable(head(mtcars), digits = 2, align = c(rep("l", 4), rep("c", 4), rep("r", 4)))
```| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.62 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.88 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.32 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.21 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.44 | 17.02 | 0 | 0 | 3 | 2 |
| Valiant | 18.1 | 6 | 225 | 105 | 2.76 | 3.46 | 20.22 | 1 | 0 | 3 | 1 |
For finer control, use the xtable package. There are tons of options (see the help file), and the interface is a bit clunky. For instance some options are passed to xtable, while others are passed to print.xtable. The key one for markdown is to use print(xtable(x), type = "html").
```{r xtable, results = 'asis'}
library(xtable)
print(xtable(head(mtcars)), type = "html")
```| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.00 | 6.00 | 160.00 | 110.00 | 3.90 | 2.62 | 16.46 | 0.00 | 1.00 | 4.00 | 4.00 |
| Mazda RX4 Wag | 21.00 | 6.00 | 160.00 | 110.00 | 3.90 | 2.88 | 17.02 | 0.00 | 1.00 | 4.00 | 4.00 |
| Datsun 710 | 22.80 | 4.00 | 108.00 | 93.00 | 3.85 | 2.32 | 18.61 | 1.00 | 1.00 | 4.00 | 1.00 |
| Hornet 4 Drive | 21.40 | 6.00 | 258.00 | 110.00 | 3.08 | 3.21 | 19.44 | 1.00 | 0.00 | 3.00 | 1.00 |
| Hornet Sportabout | 18.70 | 8.00 | 360.00 | 175.00 | 3.15 | 3.44 | 17.02 | 0.00 | 0.00 | 3.00 | 2.00 |
| Valiant | 18.10 | 6.00 | 225.00 | 105.00 | 2.76 | 3.46 | 20.22 | 1.00 | 0.00 | 3.00 | 1.00 |
The stargazer package creates good-looking tables with minimal effort. It is especially useful for summarizing a series of regression models. See the help files for all the available options.
```{r star, results = 'asis', warning=FALSE, message=FALSE}
library(stargazer, quietly = TRUE)
fit1 <- lm(mpg ~ wt, mtcars)
fit2 <- lm(mpg ~ wt + hp, mtcars)
fit3 <- lm(mpg ~ wt + hp + disp, mtcars)
stargazer(fit1, fit2, fit3, type = 'html')
```| Dependent variable: | |||
| mpg | |||
| (1) | (2) | (3) | |
| wt | -5.344*** | -3.878*** | -3.801*** |
| (0.559) | (0.633) | (1.066) | |
| hp | -0.032*** | -0.031** | |
| (0.009) | (0.011) | ||
| disp | -0.001 | ||
| (0.010) | |||
| Constant | 37.280*** | 37.230*** | 37.110*** |
| (1.878) | (1.599) | (2.111) | |
| Observations | 32 | 32 | 32 |
| R2 | 0.753 | 0.827 | 0.827 |
| Adjusted R2 | 0.745 | 0.815 | 0.808 |
| Residual Std. Error | 3.046 (df = 30) | 2.593 (df = 29) | 2.639 (df = 28) |
| F Statistic | 91.380*** (df = 1; 30) | 69.210*** (df = 2; 29) | 44.570*** (df = 3; 28) |
| Note: | p<0.1; p<0.05; p<0.01 | ||
For long-running computations, a useful chunk option is cache = TRUE. This creates a folder called cache in your working directory that will store the results of the computation after the first time you run it. After that, re-knitting the document is fast.
Figures
In general, figures will appear in a knit document exactly as they would appear in the R session. There are several important figure options to be aware of.
dev, controls the graphics device used to create the figures. For example pdf, png, or jpeg. Check outtikzDeviceif you are creating pdf output. ThetikzDevicegenerates Latex code fromRplots for use in Latex documents. That way, all fonts match the main text, and the Tex syntax for mathematics can be used directly in plots. Here are two examples of the power oftikzDevice: http://bit.ly/114GNdP, examplepathwhat directory to save the figures.fig_width,fig_height, in inches. Can also be set globally.fig_align, left, right or center.
Inline results
In my papers and reports, I strive to generate every in-text number from code. Anytime I reference a sample size, report summary statistics, or p-values in the text, paste and sprintf are my friends. Reporting in this way means no more missed corrections when you have to rerun an analysis, no more rounding errors, and the comfort that you didn’t mis-type a digit. Here are a couple examples using paste and sprintf.
paste_meansd <- function(x, digits = 2, na.rm = TRUE){
paste0(round(mean(x, na.rm = na.rm), digits), " (", round(sd(x, na.rm = na.rm), digits), ")")
}
## The mean (sd) of a random sample of normals is `r paste_meansd(rnorm(100))`The mean (sd) of a random sample of normals is 0.04 (1.01)
sprint_CI95 <- function(mu, se, trans = function(x) x) {
lim <- trans(mu + c(-1.96, 1.96)*se)
sprintf("%.2f (95%% CI: %.2f to %.2f)", mu, lim[1], lim[2])
}
bfit <- lm(hp ~ disp, mtcars)
## The coefficient estimate is `r sprint_CI95(bfit$coeff[2], sqrt(diag(vcov(bfit)))[2])`The coefficient estimate is 0.44 (95% CI: 0.32 to 0.56).
Extending knitr
Output and rendering can be customized endlessly. knitr is written in R to process chunks, so write your own functions. These types of functions are called “hooks”. For example, in this document I used a custom hook to display the code chunks as they appear:
knit_hooks$set(source = function(x, options){
if (!is.null(options$verbatim) && options$verbatim){
opts = gsub(",\\s*verbatim\\s*=\\s*TRUE\\s*", "", options$params.src)
bef = sprintf('\n\n ```{r %s}\n', opts, "\n")
stringr::str_c(
bef,
knitr:::indent_block(paste(x, collapse = '\n'), " "),
"\n ```\n"
)
} else {
stringr::str_c("\n\n```", tolower(options$engine), "\n",
paste(x, collapse = '\n'), "\n```\n\n"
)
}
})Credit: Ramnath Vaidyanathan
Output formats
Pandoc
The folks at Rstudio have worked hard to bundle knitr with pandoc, a universal document converter. Pandoc allows you to take markdown documents and convert them to almost any file format, docx, pdf, html, and much more. Furthermore, you can even convert markdown to Tex, which comes in handy for journal submission. Previously, if you wanted html output, you wrote a report in rmarkdown or rhtml and if you wanted a pdf, you had to start over with a .Rnw file. Now we can seamlessly switch between formats. The key is in defining what you want in the front matter of your document.
At the top of your markdown file, all of the pandoc parameters are put between --- delimeters. For example, in this document, I have
---
title: "knitr"
author: Michael Sachs
output:
md_document:
variant: markdown_github
---This is the front-matter, and it is in yaml format. Rstudio passes these options to pandoc to convert my document to the appropriate format, after knitting. See all of the possible options here http://rmarkdown.rstudio.com.
For example, if I want pdf output, keeping the intermediate tex file I would use
---
title: "knitr"
author: Michael Sachs
output:
pdf_document:
keep_tex: true
---Other commond document formats are word_document, html_document, and beamer_presentation. You can include a bibliography in a variety of formats, including .bib, with the bibliography: myfile.bib option. Include citations with the @bibkey syntax.
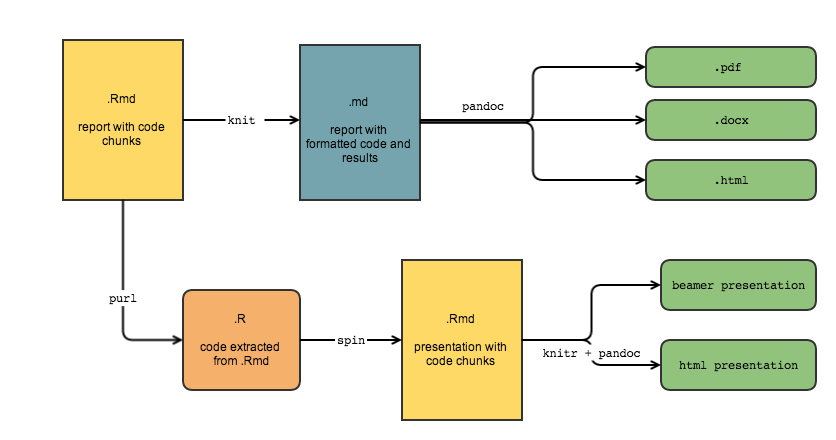
To recap, this diagram illustrates my typical workflow. I start with a .Rmd, an r-markdown document with code, background, and descriptions. knitr does the work to evaluate the code, putting the results in a markdown document, which can then be converted to a variety of formats with pandoc. To extract the R code from the original document I use the knitr::purl function. I can then easily incorporate the code chunks into other document types, like presentations.
These tools are powerful and useful for all of the beautiful reports and variety of documents you can create. More important, however, are the plain-text files that generate the reports. Writing code along with prose describing the analysis gives others and our future selves a better and clearer understanding of the analysis itself. knitr makes it easy to write analysis code for people, not computers. Do your future self a favor and start using knitr today.
Resources
Getting started
- Download the Rstudio preview release
- It comes with everything you need (except Latex)
- Menu options to create .Rmd files
- Handy button to
knitdocuments - Preview output
- Conversion to output formats uses
pandoc- Translates between semantic markup
- Endless customization
- Pass options via the front matter at the top of document
Front matter
- Document types
pdf_document,word_document,html_documentbeamer_presentation,ioslides_presentation
- Other options
bibliography: mybib.bib- Cite with
@paperkey - See http://rmarkdown.rstudio.com/ for complete documentation
Full source for this webpage available http://github.com/sachsmc/knit-git-markr-guide